在前一段时间里,我曾就TeamTalk和Telegram两款Mac下的IM软件的架构设计作了些许分析,对其亮点和不足之处给出了自己的见解。IM本身就是一个比较复杂的应用,要想做好必须是要花费一点精力的,特别是对细节的把握。倘若服务端设计本身不够理想,客户端又受限于某种并不如人愿的基础库,加之工期逼赶,家事繁忙,似乎一切天时地利都不在时,如何做出一个让自己满意的IM呢?
本文就上述并非虚构的上下文中,带领大家突破这重重枷锁,重塑架构设计,还你一个干净明了的即时通讯。技术在于分享,我并不觉得需要有任何保留,小伙伴们,拭目以待吧!
必须重塑的基础设施
俗话说,磨刀不误砍柴工,若是基础都没打好,还谈什么优良的未来?所以,在构建这个IM的第一步,便是要让基础设施部分称心如意,而前面也说过了,客户端已经受限于某个特定的基础库了。但,这个基础库并不能让我满意,或者说并不能让大多数人满意,难道这第一步就将我们打入谷底了么?我们先来看看这个基础库的现有设计。
话说就算到现在,我还是不能给这个基础库作一个设计上的定位,怎么说呢?如果说它是基础通讯组件,它不完全是;如果说它是业务共用组件,它还不那么通用,那么它的设计定位到底是什么呢?既然这样琢磨不透,那就只能往低处落了,将它作为基础通讯组件吧!
这个库完全是由C++编写,然后通过gyp自动生成了一套Objective-C++的代码,大体的使用方式如下:
- 获取某个模块的实例:
getXXX() - 注册该模块的监听:
[getXXX() RegisterObserver:xxx] - 调用某个方法,服务端返回结果,触发相应
Observer的回调
这么一说,似乎没有什么问题,但,问题往往隐藏于细节之中:
- 所有的Observer都是
Protocol,并且所有方法都是required。这导致所有的Observer必须实现一系列方法,这比你想象中的还多 - 每一个模块实例,只能注册一个Observer,这和上面一条结合起来,完全将使用者限制住了,连模块的划分都必须保持一致
- 所有服务端需要返回的方法,都是从Observer中获取结果。比如,用户更新昵称,需要从Observer中得知是否更新成功。这样使得高层组织代码会非常凌乱,加之这样的操作很多,所以,Observer中的方法真的比你想象中的还多
面对这样一个已存在的难题,如何打破这样的局限?加之高层是打算用Swift来实现,这Objective-C++是必须要进行包装后才能使用的,有个最简单的方法,就是将所有Observer使用Notification抛出去。但,这种通知满天飞的场景是你我下辈子都不愿意看见的,这样的设计会让高层使用者半夜扮鬼吓死你。
那么,我们先破除这第一道屏障,这一步不走稳,下一步还怎么迈出?
返璞归真的通讯组件
首先,我们明确一下所使用的底层组件核心问题所在,我大体罗列如下:
- 观察者不支持多路广播,也就是一个对象只能接受一个观察者
- 异步调用不够内聚、关联性不强
- 做了过多不必要的持久化操作
- 方法参数过长,命名不友好
Swift无法直接使用,必须进行包装
第三个问题由于无法干预,所以只能不去管它,这导致对内存造成了一定的浪费。其它问题统一使用一种手段解决,那就是将这层薄薄的封装打回原型,这样的决策也是让我运粮了许久,这是非常诙谐搞笑的做法,但诙谐的是我,搞笑的却另有其人。
参照Objective-C的消息设计思维,所有的方法调用都是对相应的对象发了一条消息,按照这个核心思路,我们可以把那个底层库的所有方法调用转换成一条消息的发送,观察者的返回作为异步消息的响应,具体思路可以参照以下伪代码:
1 | - (void)sendRequest:(Request *)request completion:(void (^) (Response *))completion { |
上面代码是整个底层重建的核心思想,随之带来的便是巨大的工作量,因为所有要使用的接口都必须重新包装,转换成我认为合理的方式。但回头想想,无论如何,所有接口都是需要进行包装才能被Swift使用,所以,这样的工作量是无法避免的,而这么做带来的好处便是我们拥有了一个非常纯粹的底层通讯组件。如此细粒度的拆分,给高层封装提供了更高的灵活性,不在受限与底层特定的模块和模式,也就是说,这第一道屏障算是破除了。
接下来,便是基于这样的核心思想,抽象我们的基础组件,构建一个真正适合消息系统的基础通讯设施。
消息归类
首先我们要对所有发送和接受的消息进行归类,这里所谓的发送和接收最后都会重定向到C++的那个底层库方法中,为了方便描述,我们将这个C++库命名为libMessageCore,以下便是消息的抽象类图:
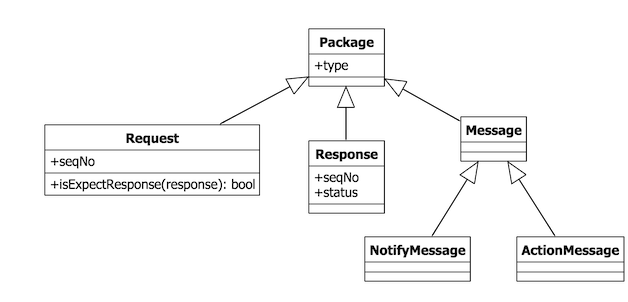
- Package:最基础的抽象,是所有消息类型的基类,代表一个数据包,
type是一个全局唯一的标识 - Request/Response:请求和响应,
seqNo用于请求和响应的匹配,由于libMessageCore中并没有这样的设计,所以这个seqNo是我们根据其它属性来实现,比如用户ID,然后请求中的isExpectResponse方法根据seqNo和其它信息来匹配响应。将响应的匹配放置在每个请求中,会比较内聚,但会略显繁琐 - Message:消息,所谓消息就是由客户端发出,或服务器推送而来,并没有强烈上下文关联的一种数据包。其子类进行了更细粒度的抽象,
NotifyMessage便是服务端推送来的消息,ActionMessage是客户端发出去的消息
按照这样归类下来,我们基本已经覆盖了通讯中会遇到的所有实体类型,那么,接下来我们再对消息实体的使用进行抽象,这会比划分类型更加有趣。
消息管道
在一个消息系统中如果没有管道的存在,那么这个消息系统是不完整的,管道类设计天生就对消息处理非常亲和,我们可以非常容易的通过装饰器模式对管道进行拦截、过滤、缓存、重定向等,而这些也都是消息系统中普遍存在的业务需求,所以,这里非常自然的就采用了管道式设计手法。由于这个通讯基础组件是基于libMessageCore之上,所以在最终设计时会略显复杂,但整个框架也变得更加通用,以下是整个消息管道设计的类图:
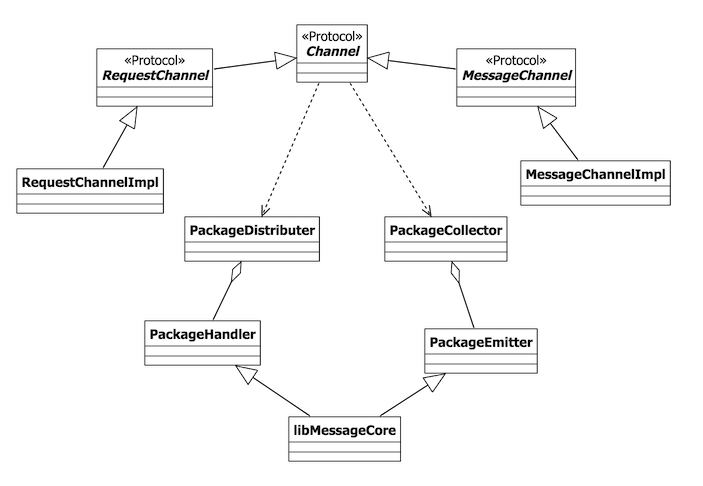
为了便于阅读,这里只展示了整个类的关系图,类的方法和属性都略去了。
- RequestChannel:请求管道,该管道负责处理
Request/Response这样一种消息模式,匹配请求和响应(_还记得isExpectResponse方法不?_),并伴有超时、缓存、异常等处理 - MessageChannel:消息管道,该管道可以添加多个观察者,用于向服务器发送
Message,并且监听服务端推送的Message,通知到所有观察者 - PackageDistributer / PackageHandler:数据包分发器和数据包处理器,分发器对高层暴露了数据包的写入接口(_主要被管道使用_),内部聚合了多个处理器,负责将数据包路由到正确的处理器上,并对处理器的寻径做了一些缓存。处理器为抽象接口,最终适配为
libMessageCore的方法调用 - PackageCollector / PackageEmitter:数据包收集器和数据包发射器,收集器可以添加多个观察者(_主要被管道观察_),内部聚合了一系列发射器,负责收集由发射器发射而来的数据包,并通知所有观察者。数据包发射器最终适配为
libMessageCore的观察者实现,通过libMessageCore的回调,构建数据包,并且发射出去
上面简单描述了几个核心抽象的职责,可能比较难以理解,所以,还是看几个时序图吧,动态的时序,相当于程序的运行时逻辑,配合上面的叙述,会更有助于理解:
![发送请求时序图] (/images/2015/08/24/03.png)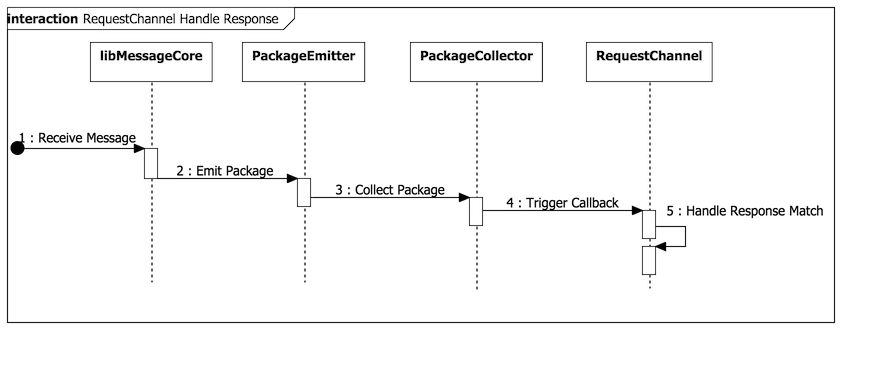
上面两个时序图,描述了整个请求响应的消息处理流程,对于MessageChannel而言,也是类似,但较RequestChannel更加简单,因为消息通道不需要做数据包匹配,也无需做超时处理,它只是单纯的成功失败,所以这里就不再展开了。
有了这样一个非常灵活轻巧的通讯组件,高层的使用代码会类似于下面这样:
1 | AccountUpdateNicknameRequest *request = [AccountUpdateNicknameRequest new]; |
看上去还是非常内聚的,并且不受限于特定的模块,我们非常愉快的解决了第一道屏障,但又给我们带来了新的挑战。那就是工作量,文章一开始就提到过:工期逼赶,所以,我们没有可能有太多的时间来撰写很多的Request/Response/Message。怎么办?花这么大气力构建的设计,难道就要这样抛弃掉?
怎么可能?那么接下来我们就来克服这个难题,缩短所需开发时间,在不缩减质量的前提下。
争分夺秒的代码生成
这些所需要编写的Package,其实有很多重复性的工作,并且,由于Objective-C语法的特性,我们也输入了很多额外的字符。那么,要节约时间,很自然的就想到了代码生成。在C#中,有 CodeSmith、T4 等很多令人印象深刻的代码生成工具,但在Objective-C这个领域,网络上似乎很难找到一款非常强大且易用的代码生成工具。
那么,怎么办呢?既然没有,那就自己手动实现一个吧,我们需要设计一个针对性很强的代码生成工具,相对而言,还是比较简单的。
语法定义
所谓代码生成,其实和编译器的概念是一样的,编译器将我们所书写的源代码转换成机器码,想象一下,这为我们省去了多少时间。那么我们需要实现的也就是一个编译器,将我们自定义的源码文件转换成所需要的各种Package定义。
类似于Protocol Buffers的定义,我将这个源码生成工具取名为Package Buffers,以下是我为它设计的语法原型:
1 | #!using "xxx.pkg" |
为了减少输入量,我将语法设计的尽量精简,省去了不必要的分号。上面便是一个语法完全合格的Package Buffers源文件,我们首要的工作是需要为这个源文件定义抽象语法树(VST),其次是实现解析器构建语法树,最后通过语法树生成我们想要的代码。
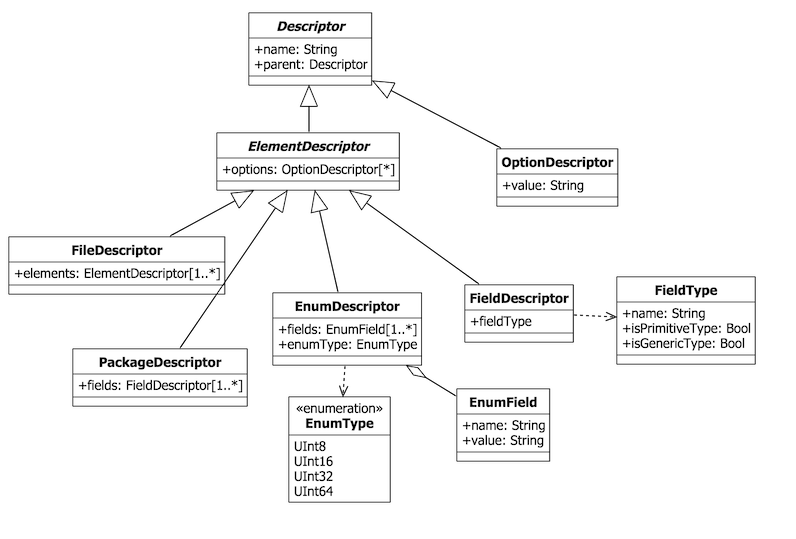
要定义语法树,我需要对这个源文件做一些说明,只有深刻的了解了语法,我们才能定义出正确的语法树。大体分为以下几个概念:
- 预编译指令:以
#!开头的内容,上面代码中的#!using就是一个预编译指令,预编译指令用在解析源码前,对源文件做预先处理 - 数据包:以
@package开头便是定义一个数据包,数据包名称紧跟其后,花括号中便是整个数据包的详细定义 - 枚举:以
@enum开头便是定义一个枚举,名称和元类型紧跟其后,花括号中是枚举的详细定义 - 字段:定义在数据包中,用空格分隔的,前面为字段类型,后面为字段名称
- 枚举字段:枚举字段与普通字段不同,它是在枚举中,没有字段类型,但有字段值
- 选项:所有以
@开头(_除去package和enum_)的基本都是选项,选项是对其所在作用域作补充说明,用于增强代码生成器的可扩展性。比如,在文件作用域中可以定义一些全局的选项,数据包作用域中定义只影响当前数据包的选项 - 注释:已
#开头的,都是可以被忽略的注释内容
有了上述的说明,我们可以将整个语法树类图构建出来了:
解析器实现
构建完语法树之后,我们就要考虑如何将源码转换成语法树了,标准的编译流程是这样的:Tokenizer -> Parser -> Expression,可以借助于ANTLR这样的工具来生成。但,我们的语法比较简单,可以直接从 Parser 到 Expression,全手动撸也不会有太多的工作量。
于是综合权衡后,决定采用Swift作为实现语言,应用递归下降分析法作为解析器的核心算法,很幸运的在 GitHub 上找到一个开源的项目,封装了一套比较好用的分析器。地址如下:
https://github.com/ollie-williams/octopus
这是一个非常简单的封装,当对于我们而言已经足够了,于是用这个库实现OptionDescriptor的解析代码如下:
1 | public struct DescriptorParser { |
其它实现类似,都是比较简单粗暴的将源码转换成了语法树,其自定义的操作符还是非常有特色的,省略了很多不必要的嵌套。当构建完解析器,也完成了所有语法树的解析时,那么接下来就需要构建生成器了,将语法树生成我们真正想要的源代码。
生成器实现
生成器的实现就非常简单了,首先通过访问者模式对语法树进行遍历,找出一些语法错误;其次再挨个的将语法树转换成代码,这个过程比较繁杂,但也不可避免。当然,我们也需要进行一些轻量级的封装,以达到下面的代码风格:
1 | func predefines() -> Writer { |
上面的代码,是将一个PackageDescriptor所定义的类和所有依赖的类预先申明在头文件中。可以看出还是比较简单的就可以实现,其它生成逻辑就不在这里赘述了,最终使用到的Package Buffers文件定义如下:
1 | #!using "CCNPackage.Constants.pkgdef" |
非常简略的定义,就可以帮我们生成很多重复性工作的代码,如此一来大概可以节约掉70%的工作量。这也是一种解决繁杂问题的思路,磨刀不误砍柴工,说得应该就是这样的道理吧!
本篇完
作为单篇博文,我思考了下,还是要尽量的减少字数,所以本系列将采用分篇的方式。这一篇下来,我们完成了整个 IM 非常基础也非常重要的底层框架,这将是整个高层设计的基石。后续,将会解开整个高层设计的神秘面纱,带你解读一系列用心良苦的设计。